I saw many industry friends at Long Beach, and we had a great discussion about Ai in the Ink Kitchen. I want to thank you so much for your participation. It was great to interact with everyone again finally. I appreciate all the input, feedback, and ideas. How often can we experience something terrifying, interesting, constantly evolving, polarizing, and challenging? It is an algorithm that is beautiful in its complexity and awe-inspiring in its massiveness.
The Diffusion Model
MidJourney is the one I have been exploring the most. It is the most illustrative, but I hesitate to use the word “creative.” It creates unique images and it is a tool to be used like any other. When using it, you are prompted to give a description that becomes a generation of an image. Midjourney is an artificial intelligence (AI) art generator that can turn text into images. It is based on the principle of Generative Adversarial Networks (GANs), a neural network that can generate new data from scratch. How it works: Training data is fed into a computer with hundreds of millions of images scraped from the internet. Take a moment to fathom the data set size, hundreds of millions of images. The image has a description, and the computer learns to identify relationships between images and words. Bias found on the internet will show up in the results. The generators favor the female form, and the images can be racist (a prompt for a “CEO” produces only white men). Reality check – BuzzFeed says it will use AI to help create content, and the stock jumped 150%.
Next, the Ai creates an internal map of relationships of concepts and converts images and text to numbers. Some correlations have a higher probability, “guitar playing” has hands, “dog walking” has a collar, and “ufo’ is a sky scene. The Ai may never have seen an image of a “guitar player walking a dog, looking at a UFO” but it has been trained to assign numbers to the database of words and images to create a data set. The images then become noise. “Visual noise is a pattern of random dots or pixels, like television static. This clutter acts as an overlay, obscuring the original image. And the model is trained to recognize that this underlying image still contains a guitar player. This is known as the “diffusion model” of machine learning, and the most popular text-to-image generators use it.”

“Diffusion Models are generative models, meaning that they are used to generate data similar to the data on which they are trained. Fundamentally, Diffusion Models work by destroying training data through the successive addition of Gaussian noise and then learning to recover the data by reversing this noising process. After training, we can use the Diffusion Model to generate data by passing randomly sampled noise through the learned denoising process.” So where we see noise… the computer still sees a guitar player, dog walking, or ufo.
Still trying to figure it out?
Let’s look a little deeper…
“Ultimately, the image is asymptotically transformed to pure Gaussian noise. Training a diffusion model aims to learn the reverse process. By traversing backward along a chain, it can generate new data.” So it destroys its own data set by using what it sees as identifiable noise and reversing the process into a new image. This kind of makes sense why its so bad at fingers and tails, because they are so constantly different in every image, it can be hard to tell if there are 1 or 2, or 5 or 7. This is why it can generate a font style but rarely anything legible, the training data is sharing concepts but text content is always different. It recognizes “Orient Express” style, but not individual letters, because in that way it would be directly stealing. Maybe when we think it’s stealing from an artist “in the style of” it’s stealing the essence, like a font style.

Infancy
So do you want to learn how to whisper? … Ai is changing very fast, so sometimes the YouTube videos do not apply anymore because you are on to a new version. In MidJourney, the easiest method is to write “/settings”
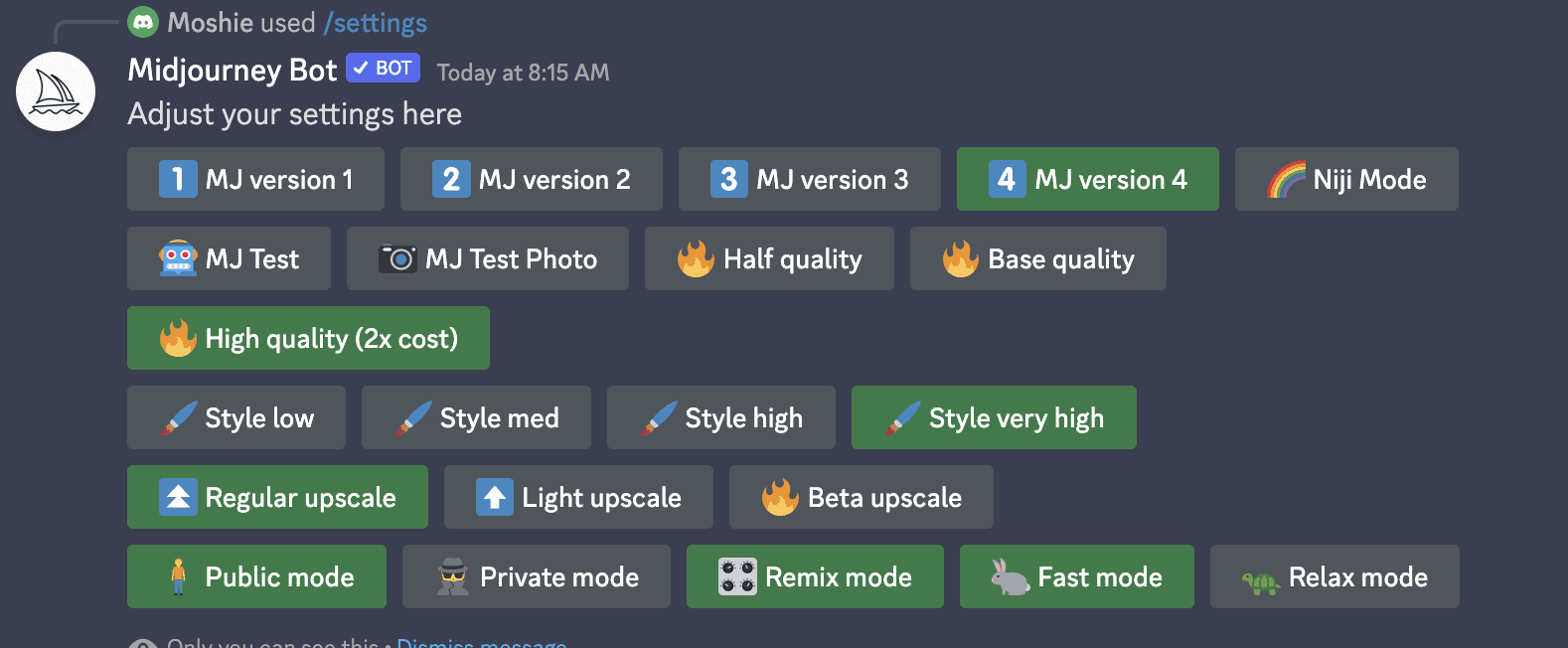
Next, you will see all the options, and you can choose what you like. Then “/imagine” and your prompt. You can also write “/info,” and you will see how much time you have. There you go; you are in the infant stage.
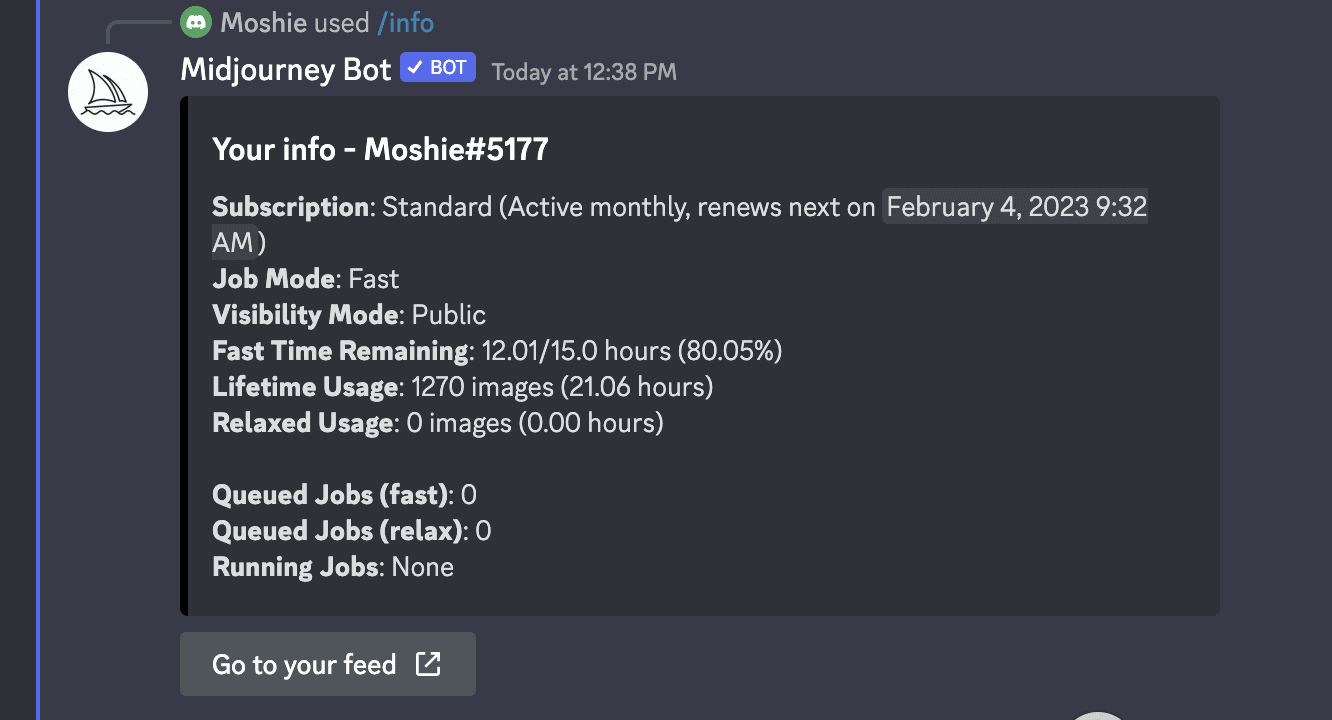
Keep in mind that there are old options and older versions, and things are changing. As I write this- things have changed, causing everyone to be up in arms, and reality is screaming back.
‘The first-ever AI-powered legal defense was set to take place in California on Feb. 22, but not anymore. The person challenging a speeding ticket would wear smart glasses that both record court proceedings and dictate responses from a small speaker into the defendant’s ear. The system relied on a few leading AI text generators, including ChatGPT and DaVinci. “Multiple state bar associations have threatened us,” Creator Browder said. “One even said a referral to the district attorney’s office and prosecution and prison time would be possible.”’
Walking
Things are shifting quickly inside the Ai and in our reality. Remember that it is hard to keep up, impossible, with hundreds of millions of images? But as you traverse, things will be discovered, unearthed, and learned. Just like any human growing up, or any Ai. Lets imagine we are generating for a t-shirt for a beachside Mexican restaurant with a toucan as its logo. We want a graphic that we can add text, and we do not have any original art to generate from. I’ve sent a prompt, /imagine “Beachside Mexican Restaurant, Toucan Logo, Black background, Isolated, Cartoon, High Definition, Colorful, Intricate –quality 2, 9:16” In this example, the unrecognized arguments are the “–quality 2, 9:16.”
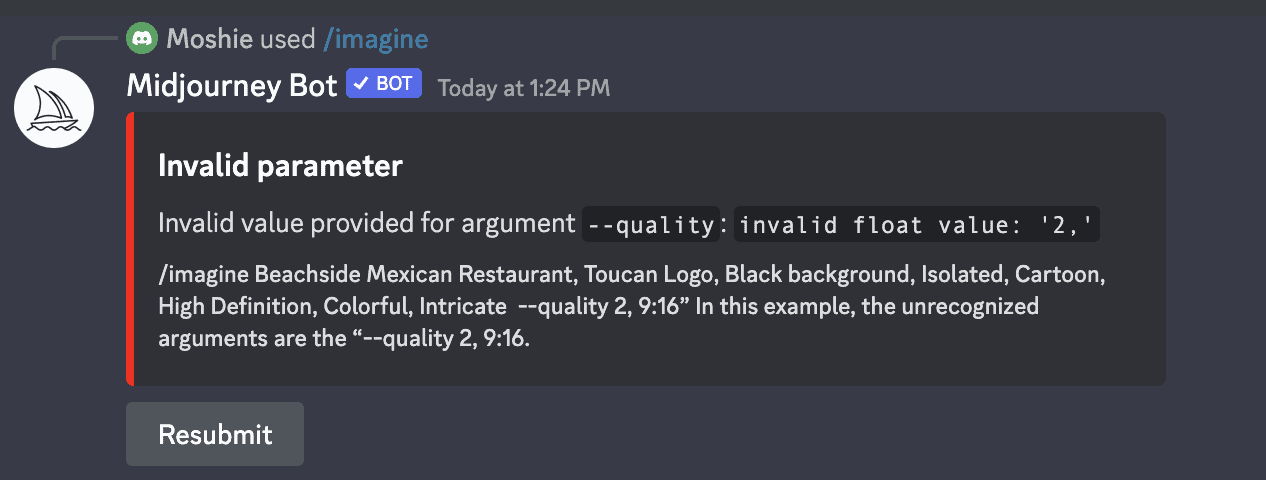
The problem is two different things. First, “—quality 2” may be an old option – so reference the /settings to pick your quality. ALSO – after you enter a prompt text, use “—“ and not anything else for qualifiers.
Lets try /imagine “Beachside Mexican Restaurant, Toucan Logo, Black background, Isolated, Cartoon, High Definition, Colorful, Intricate ”
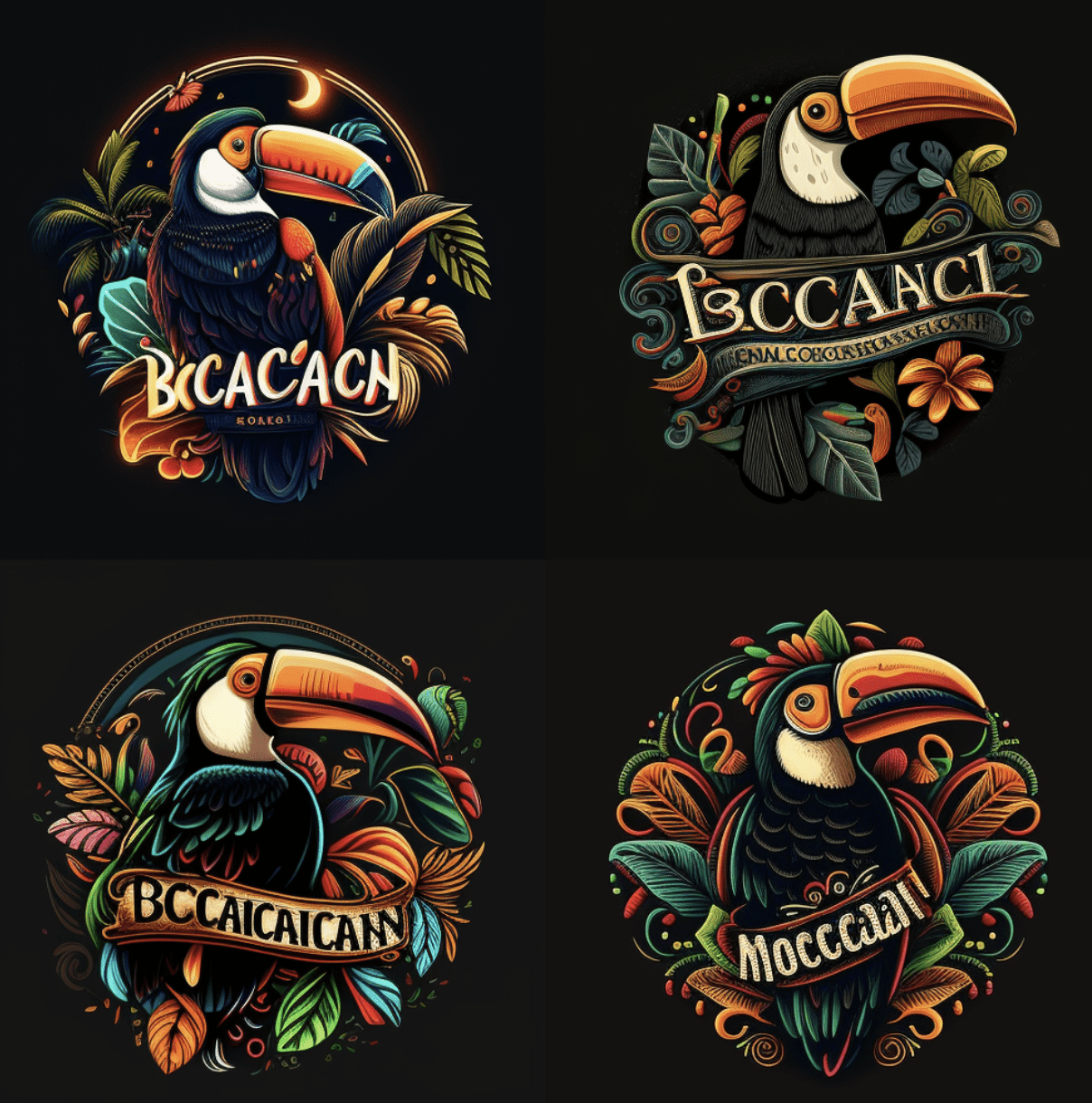
Another example /imagine “Beachside Mexican Restaurant, Toucan Logo, Black background, Isolated, Cartoon, High Definition, Colorful, Intricate —c 100 —s 1000” ….In this example, c = chaos – so —c 100 means give me four different images. And s = stylize, and on V4 —s 1000, make them very stylized. Now we are walking.

Talking
You can also write aspect ratios. It’s usually expressed as a number like 4:3 or 3:2, but there is a wide range of other sizes you can use as well. Unique aspect ratios only work in older versions, so V3, not V4. For example, /imagine “Beachside Mexican Restaurant, Toucan Logo, Black background, Isolated, Cartoon, High Definition, Colorful, Intricate —c 100 —s 1000 —ar 9:16”
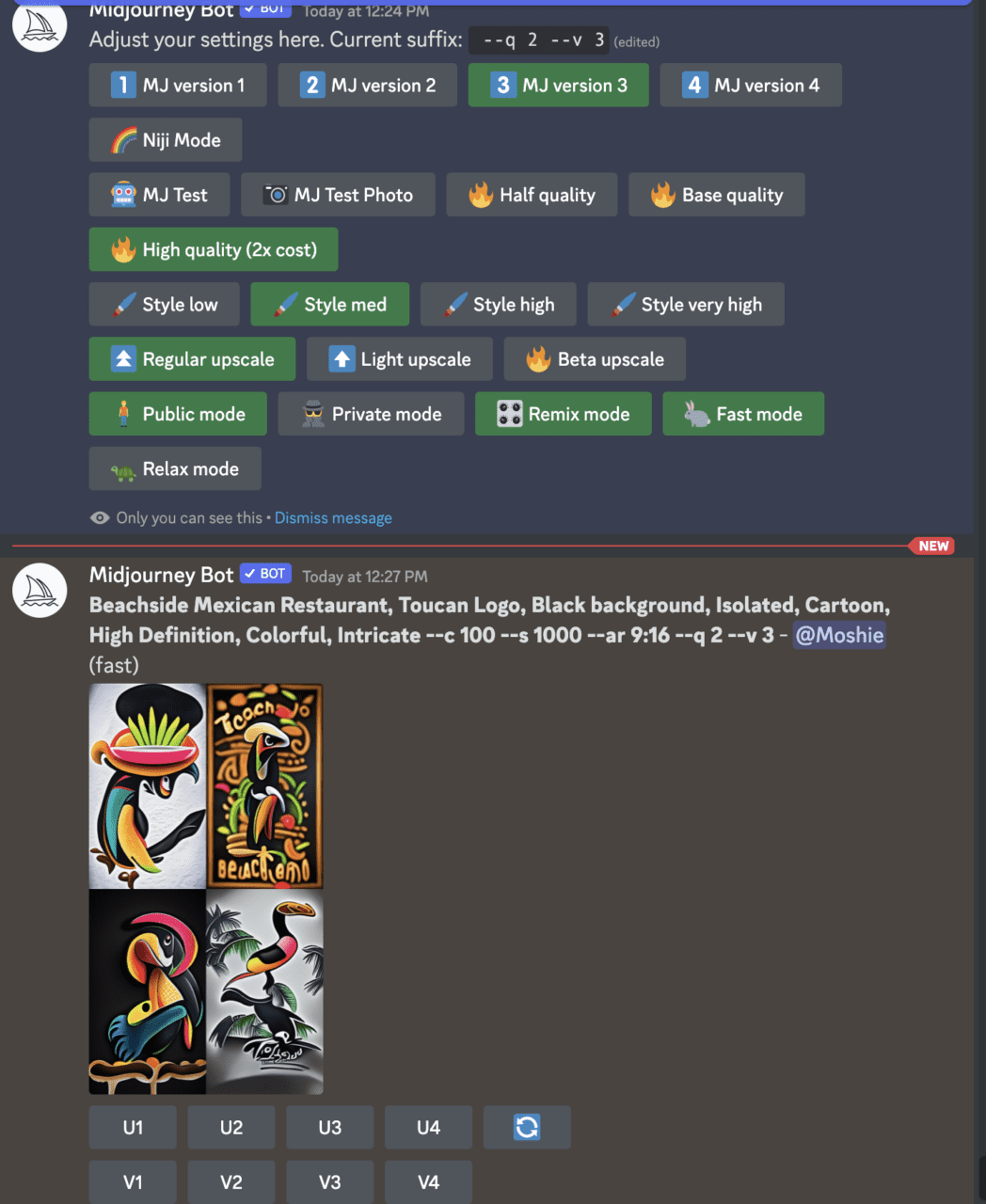
In this example, I had to switch to MidJourney V3 to use a custom aspect ratio – and I did this with /settings. Yet the generation was diminished from the original concept, and this is where learning the versions is important. Its not that one is better than the other but one may be more literal (4) and one more stylized (3). In V3, you can increase the stylization even more; this is where MidJourney gets bizarre and interesting. The stylization can be increased to 60000, and the generation will become strange and almost alien. Now we’re talkin’.

Making Friends
Some fans make that talking a reality using AI technology to make it sound like stars like Ariana Grande are singing covers of songs by Lana Del Rey, Normani , and more. One edit of Ariana singing SZA‘s “Kill Bill” even has over 2 million views on Twitter. In another it sounds like Ariana is singing Olivia Rodrigo‘s “All I Want” by using a website called BandLab. The AI transcends languages, in one Ariana’s voice sings in Spanish, Anitta’s “Envolver.” They tell the AI technology what song they want: “a party anthem in the style of Charli XCX/Ava Max.” The website creates an entire song based on the prompt criteria.
I suspect foreign MidJourney servers are a bit different than mine, which is very interesting. It uses different training data to create images. My name on MidJourney is “Moshie#5177” – we can be friends in the space. Friend me. Now we are walking, talking, and making friends.
Whispering
Maybe you are wondering if there is a way to be as detailed as possible in creating the image (which results in more similarity to what you want to obtain). You can use seeds. Think of it like this, by default, Midjourney selects a random seed value in each generation process that defines the type of noise pattern Midjourney uses to generate your desired image. This seed value is a number that introduces a random but consistent “noise” element into the process. The number itself is not particularly important since it is used to make the results random. However, it does mean that Midjourney will use a different number at each prompt, producing different results unless you define a specific seed value.
This is where the “seed command” comes in. If you don’t specify a starting value with the “seed” command, Midjourney takes a random seed value and starts from there. So we ask the Midjourney bot for the seed value it used — it’s that simple. We scroll down to the Midjourney bot-message containing this image grid, click on the message’s reaction button, and click on the envelope icon, and it produces a seed. Now we are whispering, shhh.
Refining
The first generation we did seemed to fit the theme the best, but they wanted to use a Red-crowned amazon Parrot instead of a Toucan and more beach theme. So let us change things and apply a seed value.

We switched back to version 4 and added the seed.
/imagine “Beachside Mexican Restaurant, Red-crowned amazon Parrot Logo, Beach scene, Black background, Isolated, Cartoon, High Definition, Colorful, Intricate —seed 939767272”

The first image looks good, Next Upscaling. Or U1. You can also extract video of it generating or combine multiple reference images.

Now you have a concept to create an original illustration, OR you may use this actual generation for the final. In that case, you should improve the image quality even more.
I have been using www.letsenhance.io
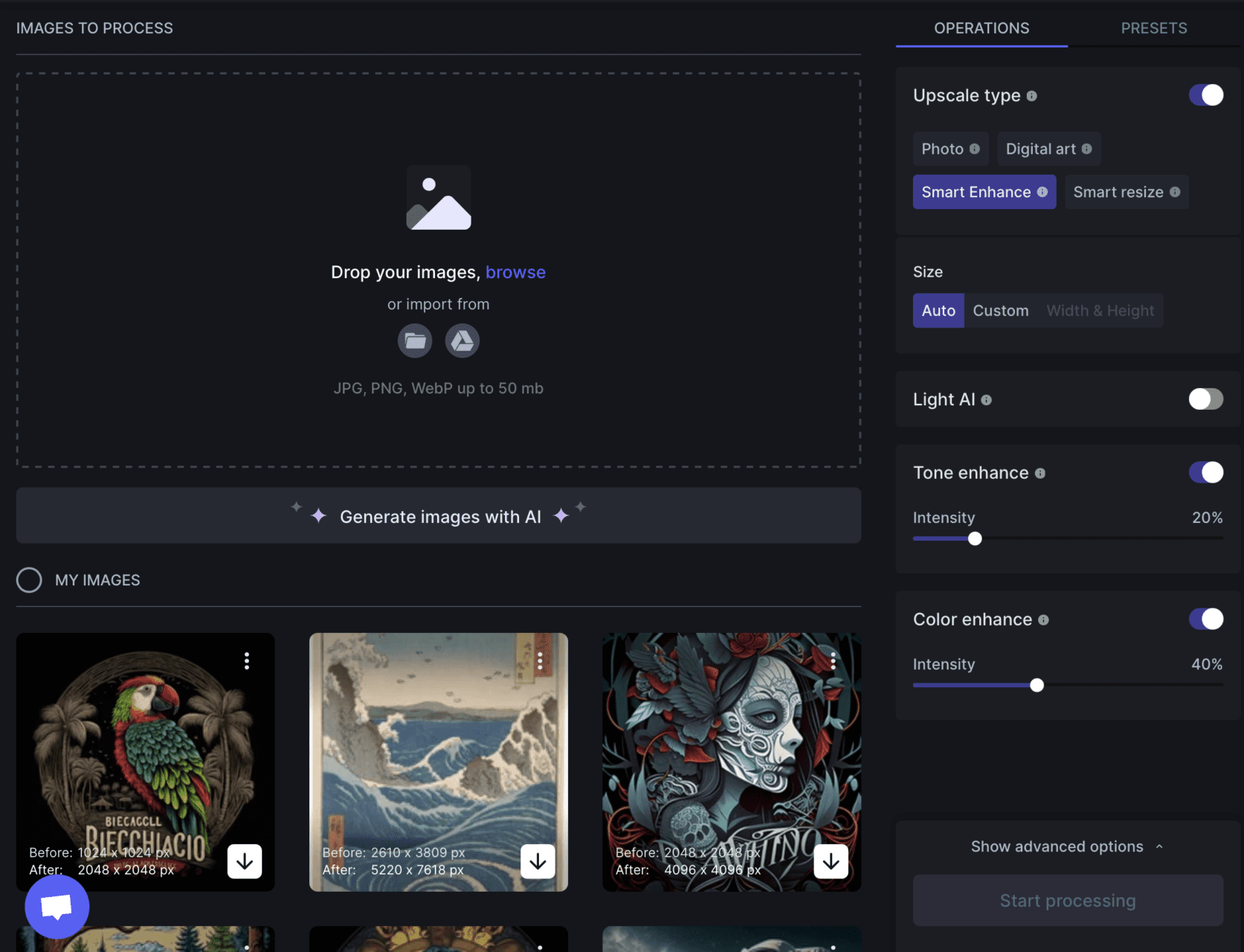
And it improves the image quality using an AI.

Learning
Did I mention things are changing very, very fast? I took a class https://www.udemy.com/course/midjourney-mastery/ and subscribed to the teacher’s YouTube updates to get started. https://www.youtube.com/delightfuldesign
I am also discovering some new teachers like https://www.tiktok.com/@rileybrown.ai?lang=es .
This stuff is mind-blowing, comment anything you are discovering too.
Next, I am taking a class next on GAN models. I am looking at the MIT class or Coursera right now.
There is another side to this, artists worldwide have expressed concerns that AI technology will make them redundant. “In December, hundreds of artists uploaded a picture saying “No to AI Generated Images” to ArtStation, one of the largest art communities on the internet, after AI-generated art appeared on the website. A few months earlier, the art world was up in arms after the Colorado State Fair’s annual art competition for emerging digital artists awarded a blue ribbon to an entrant who created his work using Midjourney.“
“A new lawsuit against Stable Diffusion, Midjourney, and DeviantArt is the first time artists have challenged generative AI companies in court. Days after that lawsuit was filed, stock-image powerhouse Getty Images filed against Stability AI in London, claiming that the company “unlawfully copied and processed millions of images protected by copyright and the associated metadata” to train its AI model.
Another group is suing Microsoft, GitHub, and OpenAI (creator of ChatGPT and image generator DALL-E 2) for making Copilot, an automatic code generator trained on existing code, available online without seeking permission from the engineers who wrote it. Last month, Stability AI announced that artists concerned about their art being used to train AI models could opt out of the next version of Stable Diffusion, a statement that generated backlash from artists who felt that the default should be “opt-in.” Mostaque acknowledged that it was a “complex issue” and said that future models of Stable Diffusion would be trained on “fully licensed” images.
Some observers have criticized the artists’ lawsuit for getting several things wrong. The suit, for instance, describes Stable Diffusion as a “collage tool that remixes the copyrighted works of millions of artists whose work was used as training data.” It also claims that AI art models “store compressed copies of [copyright-protected] training images.”
Both statements are a matter of debate. You can find out if you are being trained – here www.haveibeentrained.com
Getty released a statement:
“This week Getty Images commenced legal proceedings in the High Court of Justice in London against Stability AI claiming Stability AI infringed intellectual property rights including copyright in content owned or represented by Getty Images. It is Getty Images’ position that Stability AI unlawfully copied and processed millions of images protected by copyright and the associated metadata owned or represented by Getty Images absent a license to benefit Stability AI’s commercial interests and to the detriment of the content creators.
Getty Images believes artificial intelligence has the potential to stimulate creative endeavors. Accordingly, Getty Images provided licenses to leading technology innovators for purposes related to training artificial intelligence systems in a manner that respects personal and intellectual property rights. Stability AI did not seek any such license from Getty Images and instead, we believe, chose to ignore viable licensing options and long‑standing legal protections in pursuit of their stand‑alone commercial interests.”
Are they right? Or are they the corded telephone, newspaper, and gas-powered vehicles?
So you’re a screen company going digital – you have an existing aesthetic – Ai is a great opportunity to seed and steal, from yourself. You gain an advantage of aesthetic buildout. This is a new method for me to explore in print innovation. It’s so exciting. The lawsuits will change things, but think of them as opportunities – it steals, use it to your advantage. It knows you.
I am looking for some potential disruption projects. An Italian brand created a visual recognition disruption on woven sweaters – visual recognition will see a giraffe instead of a man. This is amazing. Imagine understanding a GAN so well that it can disrupt another Ai. Reality screams back from inside the house.

Keep in mind Ai will start screaming too, when it gets paired up with Robotics
https://www.youtube.com/watch?v=-e1_QhJ1EhQ
Have fun!


I really enjoyed this article and the way you explained AI in such clear, practical terms. It’s both exciting and a little scary to see how fast things are changing, especially for artists and creatives. Your step‑by‑step MidJourney examples and the discussion of legal and ethical issues gave me a lot to think about. Thanks for sharing your experience and resources – they make this complex topic feel much more approachable.
Thanks 🙂 I thought I would share my learning journey with everyone. If you keep going, it’s called °F AI – Fahrenheit Ai. It evolves into that from here, so there’s a year of vlogs on the In Kitchen YouTube, and then I’m back on here writing blogs about how I’m using AI day to day.